Design effects for stratified sub-populations
16 November 2024
I look at the two different sorts of design effects that Stata will report for estimates from sub-populations of a complex survey, which vary depending on whether or not the hypothetical simple random sample we are comparing the complex survey to has the same sub-population sample sizes as the actual sample.

Gender and sexuality in Australian surveys and census
08 September 2024
I familiarise myself with the Australian Bureau of Statistics' statistical Standard on sex and gender, and play around with some data from the Australian General Social Survey that has outputs reported by persons' sexual orientation.

Sampling without replacement with unequal probabilities
31 August 2024
I play around with sampling from finite populations with unequal probabilities, where the R sample() function turns out not to work the way I had expected it to.

Weighted versus unweighted percentiles
24 June 2023
When working with complex survey data where the weights are related to a continuous variable of interest, using a weighted rather than unweighted percentile rank will lead to different results towards the middle of the distribution; but the two measures will be highly correlated with eachother. Also, R reportedly calculates weighted percentile ranks much much faster than Stata.

Facebook survey data for the Covid-19 Symptom Data Challenge
04 October 2020
Two huge surveys of Facebook users seem to provide valuable new information on how the world is responding to Covid-19, but I am very unsure about whether they have potential to enable earlier detection of outbreaks.

Free text in surveys - important issues in the 2017 New Zealand Election Study
26 September 2020
I try out biterm topic modelling on a free text question in the 2017 New Zealand Election Study about the most important issue in the election.

New Zealand Election Study webtool
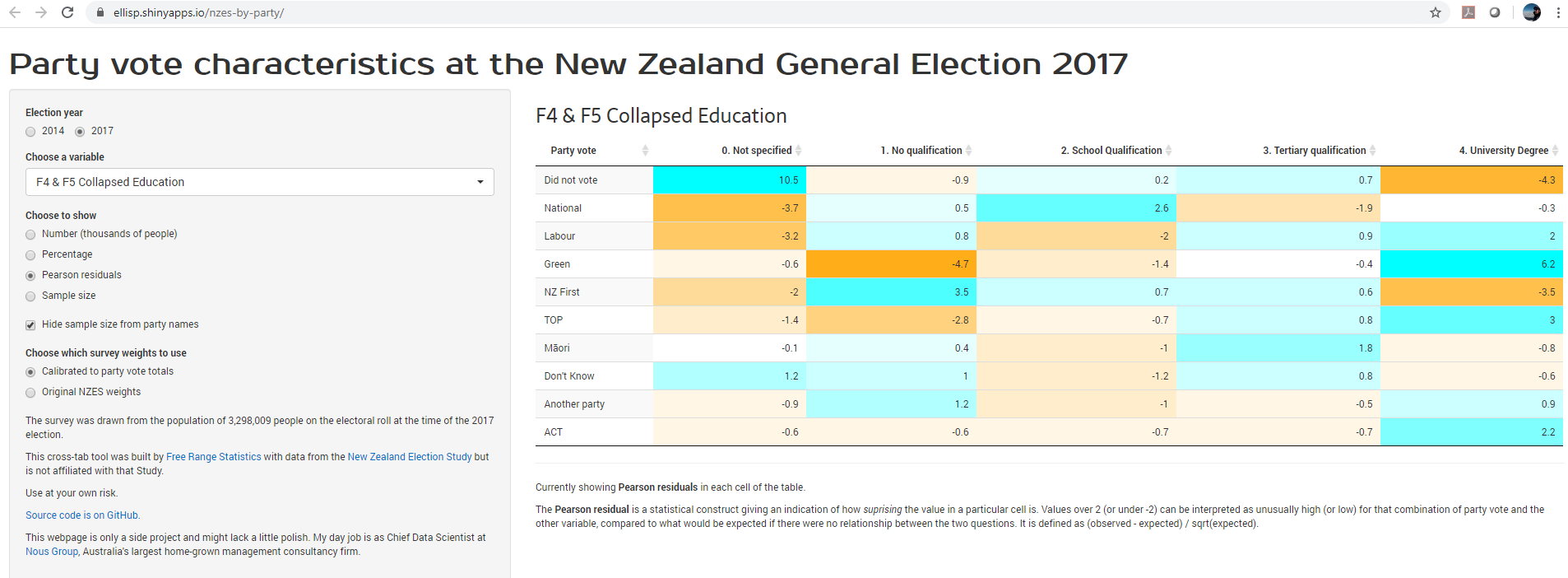
07 March 2020
I release an improved and updated version of my crosstab webtool for exploring the New Zealand Election Study data, now covering 2017 as well as 2014, and letting the user explore relationship between party vote and a range of attitudes, experiences and demographics.
Log transform or log link? And confounding variables.
01 March 2020
I check the robustness of last week's analysis of height -> weight by trying a different method of specifying and fitting the model, and checking to see if socioeconomic status is acting as a confounder (because better-off people are both taller and healthier).

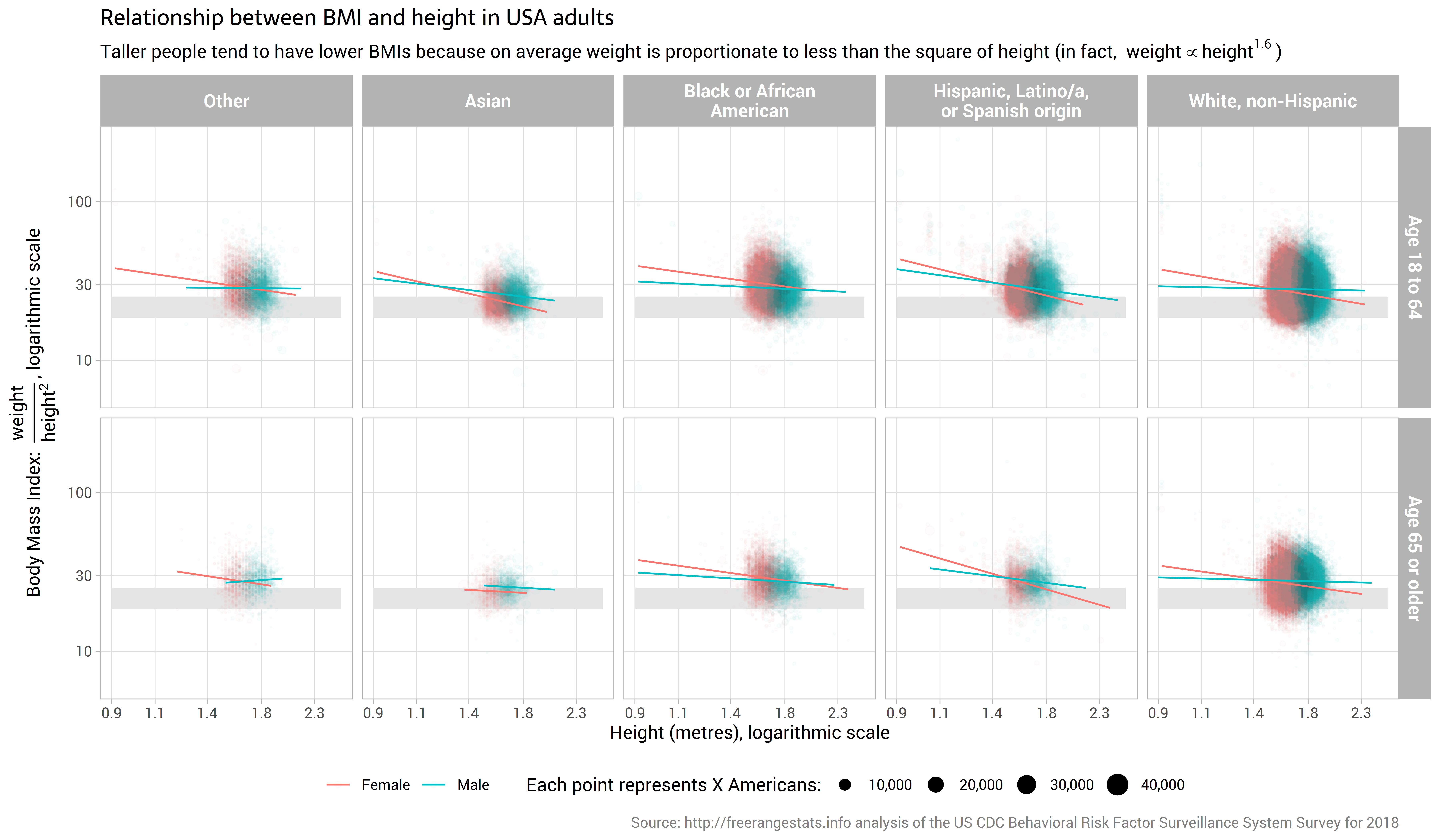
Body Mass Index
23 February 2020
I test the traditional BMI calculation against the actual distribution of height and weight in USA adults in 2018. I decide BMI is quite a good metric. I find that one prominent critique of the BMI gets the direction wrong for whom has their weight exaggerated by BMI.
Re-creating survey microdata from marginal totals
03 November 2019
I play around with creating my own synthetic unit record file of survey microdata to match published marginal totals. I conclude that making synthetic data for development or education purposes can be useful, but the effort to try to exactly match marginal totals from this sort of survey is unlikely to be useful for either bona fide researchers or ill-intentioned data snoopers.

Polls v results
19 May 2019
The polls did worse than usual in predicting the Australian federal election, but the pundits were far worse than the polls.

House effects, herding, and the last few days before the election
15 May 2019
A few small explorations of idiosyncracies with polls, a couple of days before the Australian federal election.

Familiarisation with the Australian Election Study
22 April 2019
I familiarise myself with the 2016 Australian Election Study, a wonderful source of individual level data on attitudes and behaviour relating to voting.

Bayesian state space modelling of the Australian 2019 election
02 March 2019
I tidy up Australian polling data back to 2007 and produce a statistical model of two-party-preferred vote for the coming election.

Seasonality in NZ voting preference?
20 February 2019
I update the nzelect R package with the latest New Zealand polling data, and use a generalized additive model to look for a seasonal impact on support for the current government.

What the world agrees with
26 January 2019
I load wave 6 of the World Values Survey into a database so it's possible to analyse more questions and countries at once, and find some interesting variations in what people agree with in different parts of the world.

Estimating relative risk in a simulated complex survey
24 August 2018
Simulating complex survey data in order to fit slightly mis-specified relative risk models, we find that confidence intervals' coverage is pretty much as advertised if we use appropriate methods that adjust for the complex survey data, but under-perform if the data is treated naively as coming from a simple random sample.

Survey books, courses and tools
05 May 2018
Books, online courses and tools on surveys I've recently visited and liked.

Weighted survey data with Power BI compared to dplyr, SQL or survey
11 April 2018
I show a workaround to make it (relatively) easy to work with weighted survey data in Power BI, and ruminate on how this compares to other approaches of working with weighted data.

Average spend, activities and length of visit in the NZ International Visitor Survey
03 February 2018
Resolving an apparent conundrum where the mean spend and other value variables seems to be higher for nearly everywhere... an adventure in double counting (individuals contributing to multiple groups' averages).

nzelect 0.4.0 on CRAN with results from 2002 to 2014 and polls up to September 2017
05 October 2017
A new version of the nzelect R package is on CRAN, with election results by voting location back to 2002, and polls up to the latest election. I show how to extract and understand the "special" votes and how they are different to advance voting.

Time-varying house effects in New Zealand political polls
16 September 2017
I adjust my state-space model of New Zealand voting behaviour to allow for the house effect of one of the pollsters to change from the time they started including an on-line sample, and get some interesting results.

The long view on New Zealand political polls
09 September 2017
New Zealand electoral polls going back 15 years

More things with the New Zealand Election Study
20 August 2017
I introduce a new web app that allows nons-specialists to explore voting behaviour in the New Zealand Election Study, and reflect on what I've done so far with that data.
State-space modelling of the Australian 2007 federal election
24 June 2017
As part of familiarising myself with the Stan probabilistic programming language, I replicate Simon Jackman's state space modelling with house effects of the 2007 Australian federal election.

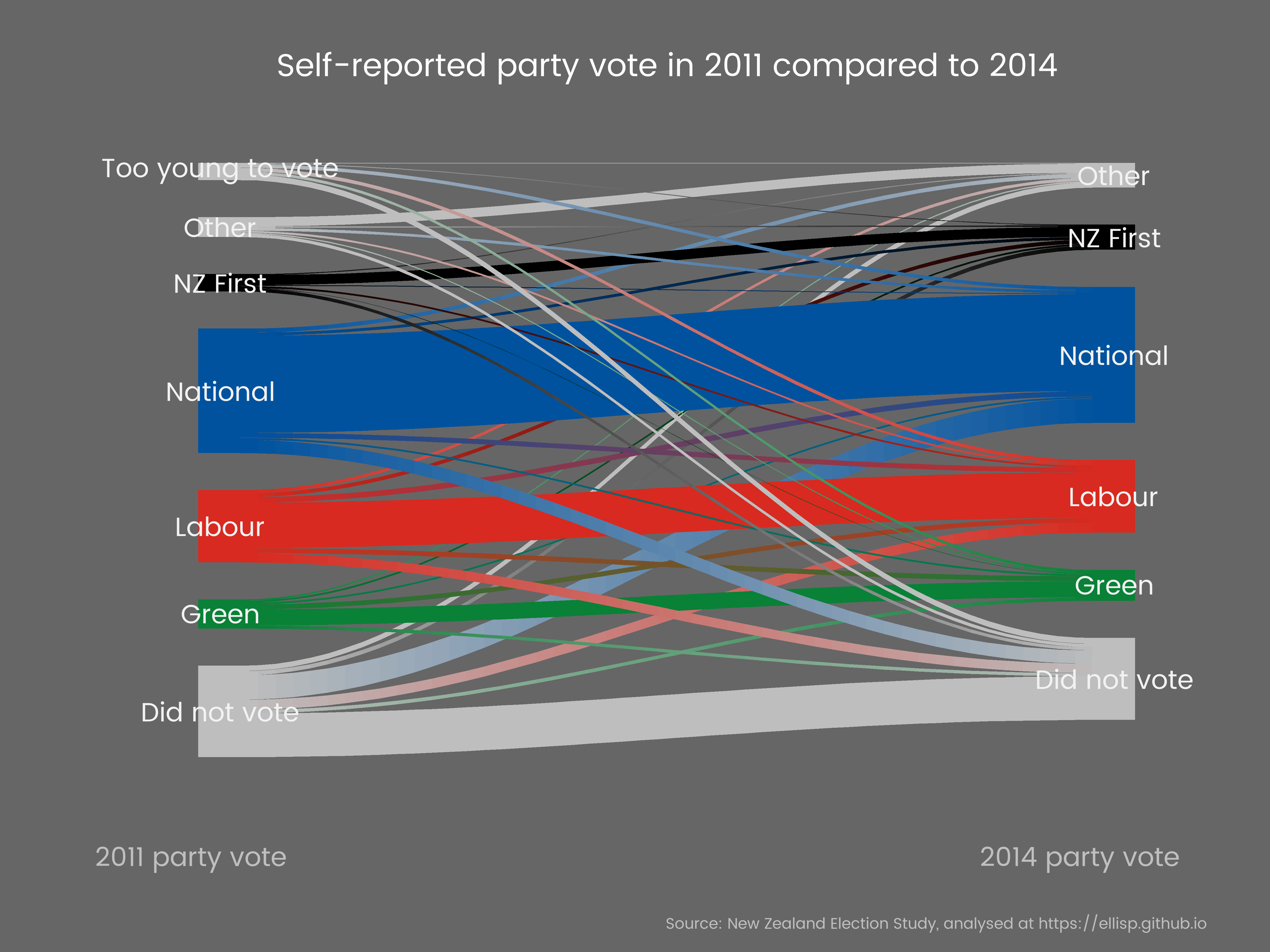
Sankey charts for swinging voters
21 May 2017
Sankey charts based on individual level survey data are a good way of showing change from election to election. I demonstrate this, via some complications with survey-reweighting and missing data, with the New Zealand Election Study for the 2014 and 2011 elections.
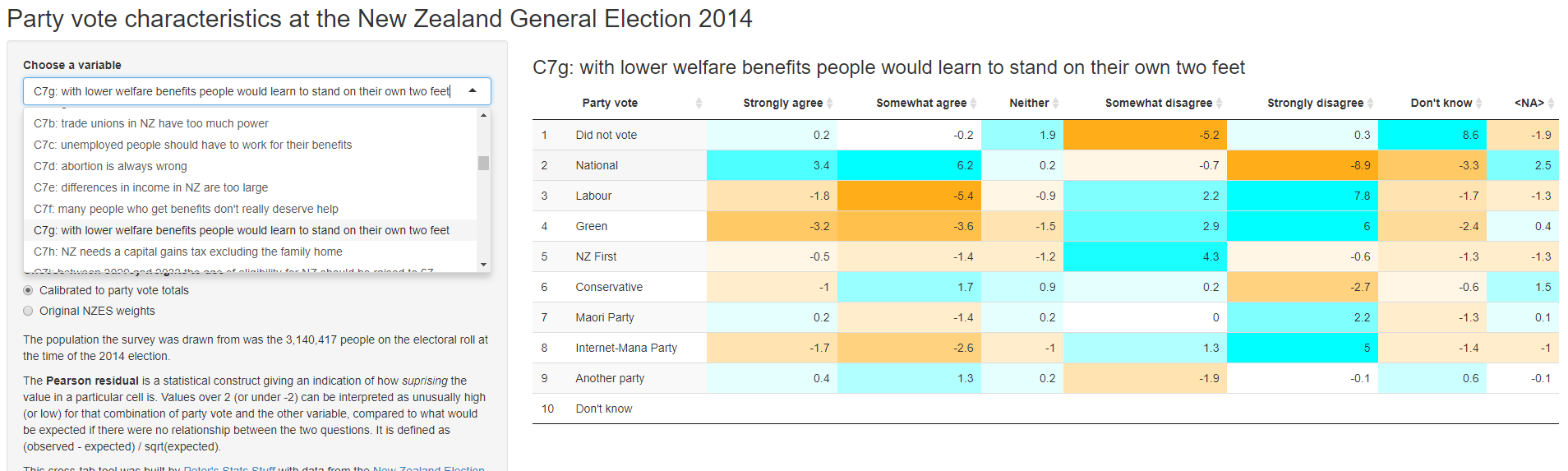
Web app for individual party vote from the 2014 New Zealand election study
14 May 2017
Introducing a Shiny web tool for exploring individual characteristics and party vote in the 2014 New Zealand general election.
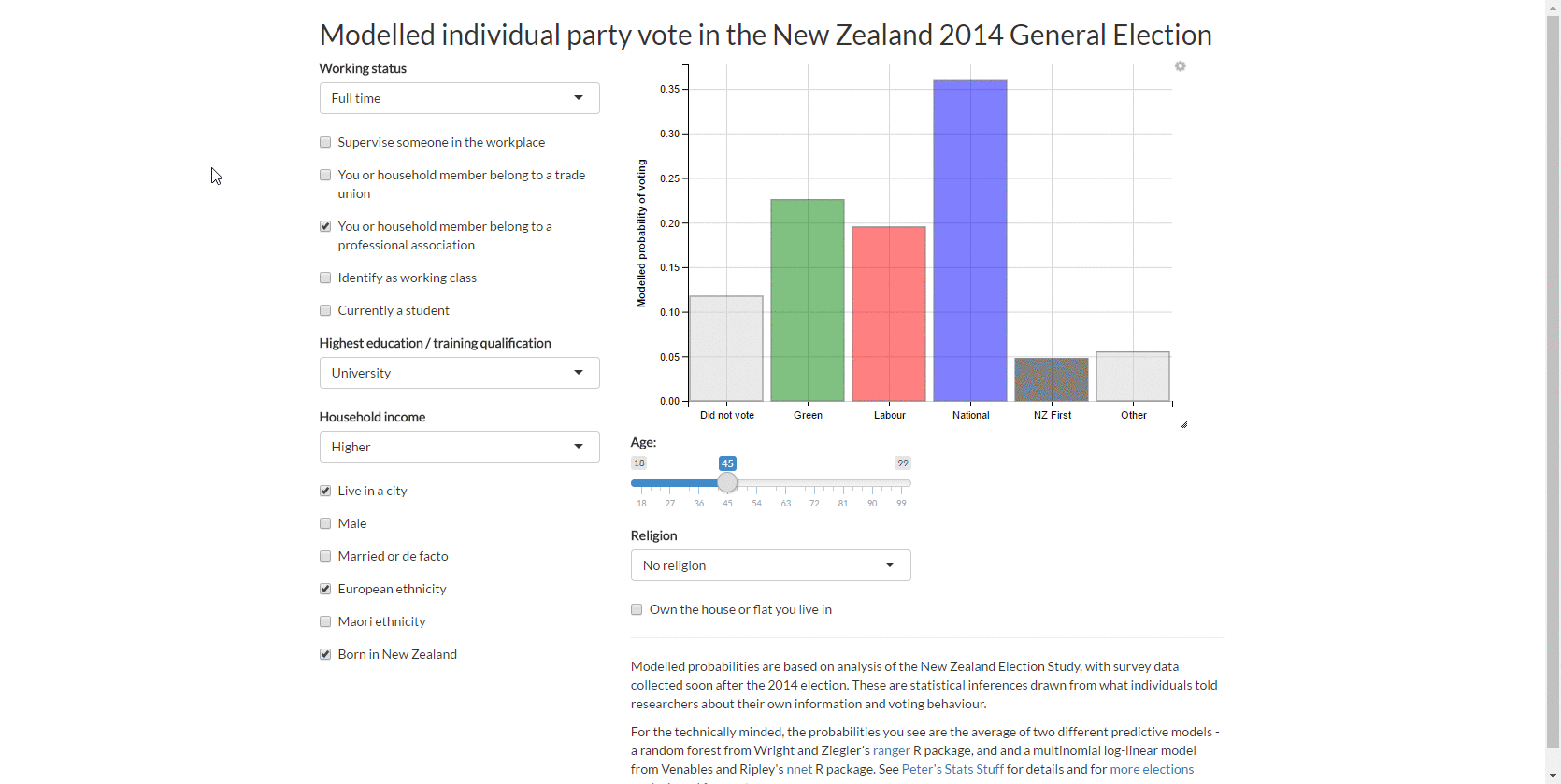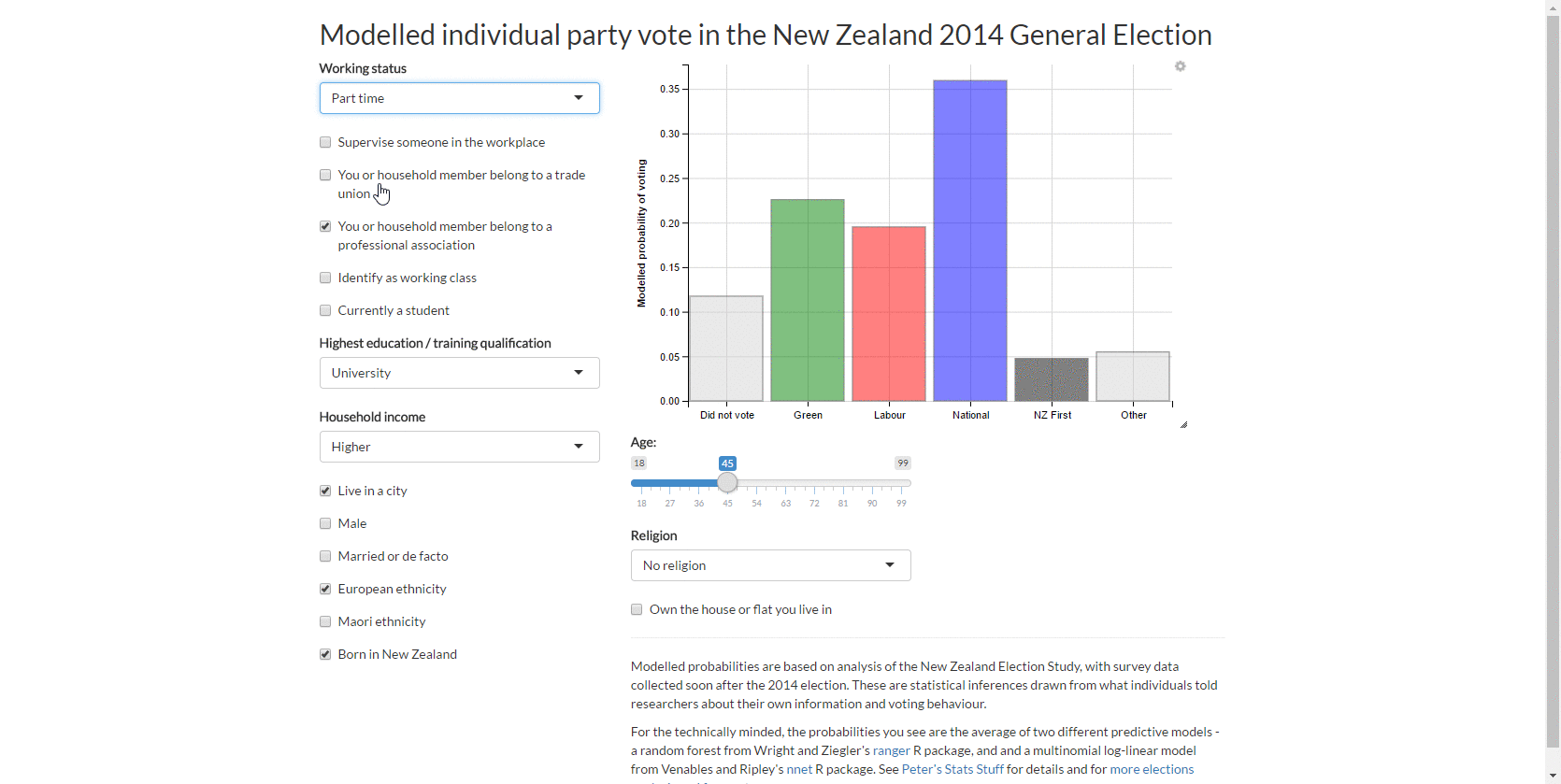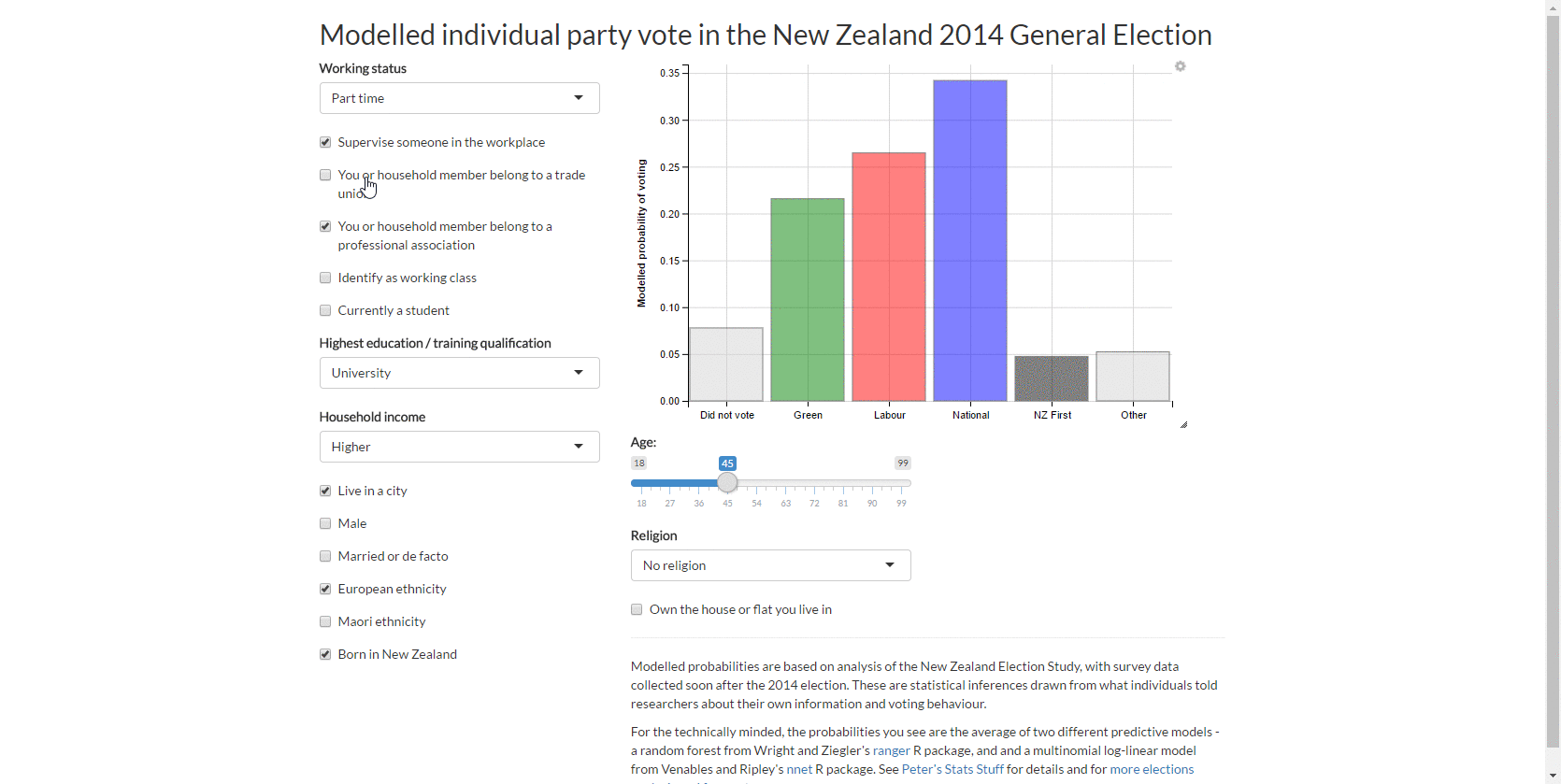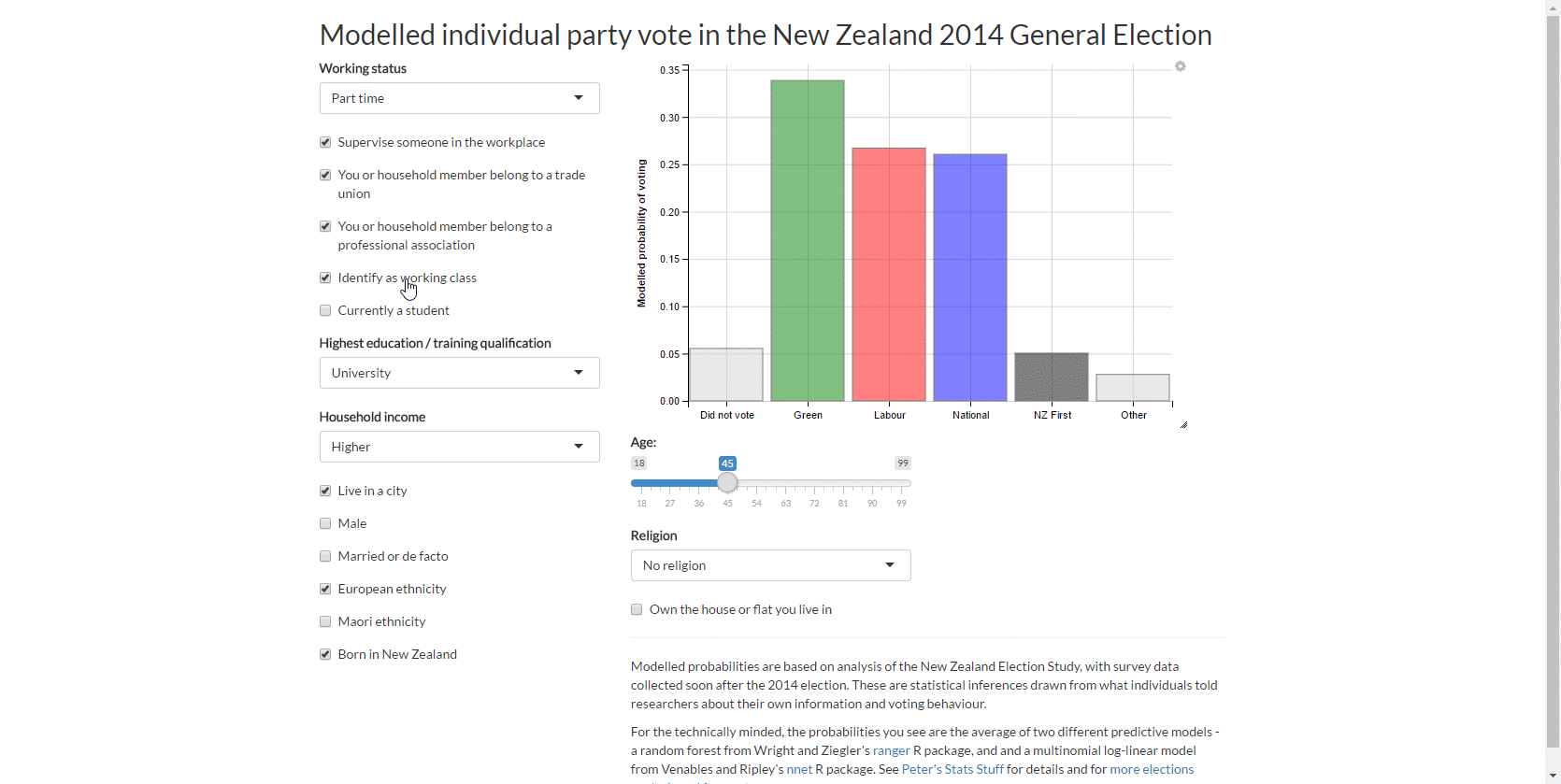
Modelling individual party vote from the 2014 New Zealand election study
06 May 2017
I work through a fairly complete modelling case study utilising methods for complex surveys, multiple imputation, multilevel models, non-linear relationships and the bootstrap. People who voted for New Zealand First in the 2014 election were more likely to be older, born in New Zealand, identify as working class and male.

House effects in New Zealand voting intention polls
21 March 2017
I use generalized additive models to explore "house effects" (ie statistical bias) in polling firms' estimates of vote in previous New Zealand elections.

New data and functions in nzelect 0.3.0 R package
11 March 2017
Version 0.3.0 of the nzelect R package now on CRAN includes historical polling data and a few convenience functions

FiveThirtyEight's polling data for the US Presidential election
29 October 2016
I have a quick look at the polling data used by the FiveThirtyEight website in predicting the USA presidential election results

New Zealand Election Study individual level data
18 September 2016
Individual level data on voting behaviour are freely available from the New Zealand Election Study and everyone should have a go at analysing them!

Importing the New Zealand Income Survey SURF
15 August 2015
I tidy up the publicly available simulated unit record file (SURF) of the New Zealand Income Survey 2011, import into a database, and explore income distributions, visualising the lower distribution of weekly incomes New Zealanders of Maori and Pacific Islander ethnicity. Along the way I create a function to identify modes in a multi-modal distribution.
