Continuing my examination of the individual level voting behaviour from the New Zealand Election Study, I wanted to look at the way individuals swap between parties, and between “did not vote” and a party, from one election to another. How much and how this happens is obviously an important question for both political scientists and for politicians.
Vote transition visualisations
I chose a Sankey chart as a way of showing the transition matrix from self-reported party vote in the 2011 election to the 2014 election. Here’s a static version:
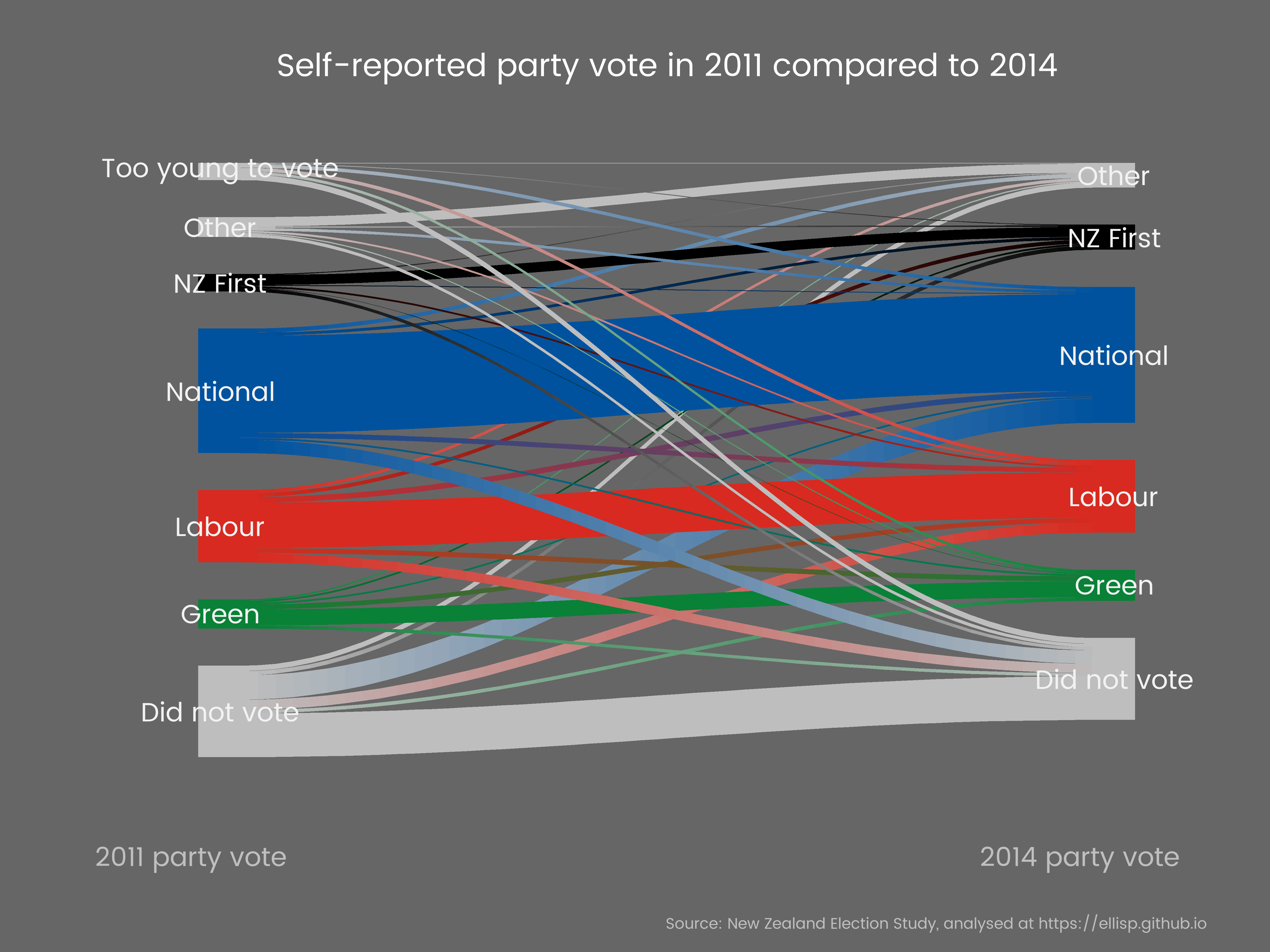
And here is the more screen-friendly interactive version, with mouseover tooltips to give actual estimates:
The point with these graphics is to highlight the transitions. For example, what were the implications of turnout being higher in 2014 than 2011 (77.9% of enrolled voters in 2014 compared to 74.2% in 2011)? Judging from this survey data, the National Party gained 6.6% of the enrolled population in 2014 by converting them from a 2011 “did not vote” and lost only 3.6% in the other direction. This net gain of three percentage points was enough to win the election for the National-led coalition. In contrast, the Labour party had a net gain from “did not vote” in 2011 of only 0.2 percentage points. Remember though that these are survey-based estimates, and subject to statistical error.
I find setting up and polishing Sankey charts - controlling colours for example - a bit of a pain, so the code at the bottom of this post on how this was done might be of interest.
Weighting, missing data, population and age complications
Those visualisations have a few hidden fishhooks, which careful readers would find if they compare the percentages in the tooltips of the interactive version with percentages reported by the New Zealand Electoral Commission.
- The 2014 percentages are proportions of the enrolled population. As the 2014 turnout of enrolled voters was 77.9%, the numbers here are noticeably less than the usually cited percentages which were used to translate into seat counts (for example, National Party reported party vote of 47.0% of votes becomes 36.6% of enrolled voters)
- The 2011 percentages are even harder to explain, because I’ve chosen not only to scale the party vote and “did not vote” to the 2011 enrolled population as reported by the Commission, but also to add in around 5% of the 2014 population that were too young to vote in 2011.
Two things I would have liked to have taken into account but wasn’t able to were:
- The “leakage” from the 2011 election of people who were deceased or had left the country by 2014
- Explicit recognition of people who voted in 2014 but not in 2011 because they were out of the country. There is a variable in the survey that picks up the year the respondent came to live in New Zealand if not born here, but for only 10 respondents was this 2012 or later (in contrast to age - there were 58 respondents aged 20 or less in 2014).
I re-weighted the survey so the 2014 and 2011 reported party votes matched the known totals (with the addition of people aged 15 to 17 in 2011). One doesn’t normally re-weight a survey based on answers provided by the respondents, but in this case I think it makes perfect sense to calibrate to the public totals. The biggest impact is that for both years, but particularly 2011, relying on the respondents’ self-report and the published weighting of the NZES, totals for “did not vote” are materially understated, compared to results when calibrated to the known totals.
When party vote in 2011 had been forgotten or was an NA, and this wasn’t explained by being too young in 2011, I used multiple imputation based on a subset of relevant variables to give five instances of probable party vote to each such respondent.
Taken together, all this gives the visualisations a perspective based in 2014. It is better to think of it as “where did the 2014 voters come from” than “where did the 2011 voters go”. This is fairly natural when we consider it is the 2014 New Zealand Election Study, but is worth keeping in mind in interpretation.
Age (and hence the impact new young voters coming in, and of older voters passing on) is important in voting behaviour, as even the most casual observation of politics shows. In New Zealand, the age distribution of party voters in 2014 is seen in the chart below:

Non-voters, Green voters and to a certain extent Labour voters are young; New Zealand First voters are older. If this interests you though, I suggest you look at the multivariate analysis in this blog post or, probably more fun, this fancy interactive web app which lets you play with the predicted probabilities of voting based on a combination of demographic and socio-economic status variables.
Code
Here’s the R code that did that imputation, weighting, and the graphics:
library(tidyverse)
library(forcats)
library(riverplot)
library(sankeyD3)
library(foreign)
library(testthat)
library(mice)
library(grid)
library(survey)
# Caution networkD3 has its own sankeyD3 with less features. Make sure you know which one you're using!
# Don't load up networkD3 in the same session
#============import data======================
# See previous blog posts for where this comes from:
unzip("D:/Downloads/NZES2014GeneralReleaseApril16.sav.zip")
nzes_orig <- read.spss("NZES2014GeneralReleaseApril16.sav",
to.data.frame = TRUE, trim.factor.names = TRUE)
# Five versions of each row, so when we do imputation later on we
# in effect doing multiple imputation:
nzes <- nzes_orig[rep(1:nrow(nzes_orig), each = 5), ] %>%
# lump up party vote in 2014:
mutate(partyvote2014 = ifelse(is.na(dpartyvote), "Did not vote", as.character(dpartyvote)),
partyvote2014 = gsub("M.ori", "Maori", partyvote2014),
partyvote2014 = gsub("net.Man", "net-Man", partyvote2014),
partyvote2014 = fct_infreq(partyvote2014)) %>%
mutate(partyvote2014 = fct_lump(partyvote2014, 5))
# party vote in 2011, and a smaller set of columns to do the imputation:
nzes2 <- nzes %>%
mutate(partyvote2011 = as.factor(ifelse(dlastpvote == "Don't know", NA, as.character(dlastpvote)))) %>%
# select a smaller number of variables so imputation is feasible:
select(dwtfin, partyvote2014, partyvote2011, dethnicity_m, dage, dhhincome, dtradeunion, dprofassoc,
dhousing, dclass, dedcons, dwkpt)
# impute the missing values. Although we are imputing only a single set of values,
# because we are doing it with each row repeated five times this has the same impact,
# for the simple analysis we do later on, as multiple imputation:
nzes3 <- complete(mice(nzes2, m = 1))
# Lump up the 2011 vote, tidy labels, and work out who was too young to vote:
nzes4 <- nzes3 %>%
mutate(partyvote2011 = fct_lump(partyvote2011, 5),
partyvote2011 = ifelse(grepl("I did not vote", partyvote2011), "Did not vote", as.character(partyvote2011)),
partyvote2011 = ifelse(dage < 21, "Too young to vote", partyvote2011),
partyvote2014 = as.character(partyvote2014))
#===============re-weighting to match actual votes in 2011 and 2014===================
# This makes a big difference, for both years, but more for 2011. "Did not vote" is only 16% in 2011
# if we only calibrate to 2014 voting outcomes, but in reality was 25.8%. We calibrate for both
# 2011 and 2014 so the better proportions for both elections.
#------------2014 actual outcomes----------------
# http://www.elections.org.nz/news-media/new-zealand-2014-general-election-official-results
actual_vote_2014 <- data_frame(
partyvote2014 = c("National", "Labour", "Green", "NZ First", "Other", "Did not vote"),
Freq = c(1131501, 604534, 257356, 208300,
31850 + 16689 + 5286 + 95598 + 34095 + 10961 + 5113 + 1730 + 1096 + 872 + 639,
NA)
)
# calculate the did not vote, from the 77.9 percent turnout
actual_vote_2014[6, 2] <- (100 / 77.9 - 1) * sum(actual_vote_2014[1:5, 2])
# check I did the turnout sums right:
expect_equal(0.779 * sum(actual_vote_2014[ ,2]), sum(actual_vote_2014[1:5, 2]))
#---------------2011 actual outcomes---------------------
# http://www.elections.org.nz/events/past-events-0/2011-general-election/2011-general-election-official-results
actual_vote_2011 <- data_frame(
partyvote2011 = c("National", "Labour", "Green", "NZ First", "Other", "Did not vote", "Too young to vote"),
Freq = c(1058636, 614937, 247372, 147511,
31982 + 24168 + 23889 + 13443 + 59237 + 11738 + 1714 + 1595 + 1209,
NA, NA)
)
# calculate the did not vote, from the 74.21 percent turnout at
# http://www.elections.org.nz/events/past-events/2011-general-election
actual_vote_2011[6, 2] <- (100 / 74.21 - 1) * sum(actual_vote_2011[1:5, 2])
# check I did the turnout sums right:
expect_equal(0.7421 * sum(actual_vote_2011[1:6 ,2]), sum(actual_vote_2011[1:5, 2]))
# from the below, we conclude 4.8% of the 2014 population (as estimated by NZES)
# were too young to vote in 2011:
nzes_orig %>%
mutate(tooyoung = dage < 21) %>%
group_by(tooyoung) %>%
summarise(pop = sum(dwtfin),
n = n()) %>%
ungroup() %>%
mutate(prop = pop / sum(pop))
# this is pretty approximate but will do for our purposes.
actual_vote_2011[7, 2] <- 0.048 * sum(actual_vote_2011[1:6, 2])
# Force the 2011 numbers to match the 2014 population
actual_vote_2011$Freq <- actual_vote_2011$Freq / sum(actual_vote_2011$Freq) * sum(actual_vote_2014$Freq)
#------------create new weights--------------------
# set up survey design with the original weights:
nzes_svy <- svydesign(~1, data = nzes4, weights = ~dwtfin)
# calibrate weights to the known total party votes in 2011 and 2014:
nzes_cal <- calibrate(nzes_svy,
list(~partyvote2014, ~partyvote2011),
list(actual_vote_2014, actual_vote_2011))
# extract those weights for use in straight R (not just "survey")
nzes5 <- nzes4 %>%
mutate(weight = weights(nzes_cal))
# See impact of calibrated weights for the 2014 vote:
prop.table(svytable(~partyvote2014, nzes_svy)) # original weights
prop.table(svytable(~partyvote2014, nzes_cal)) # recalibrated weights
# See impact of calibrated weights for the 2011 vote:
prop.table(svytable(~partyvote2011, nzes_svy)) # original weights
prop.table(svytable(~partyvote2011, nzes_cal)) # recalibrated weights
#=======================previous years vote riverplot version============
the_data <- nzes5 %>%
mutate(
# add two spaces to ensure the partyvote2011 does not have any
# names that exactly match the party vote in 2014
partyvote2011 = paste(partyvote2011, " "),
partyvote2011 = gsub("M.ori", "Maori", partyvote2011)) %>%
group_by(partyvote2011, partyvote2014) %>%
summarise(vote_prop = sum(weight)) %>%
ungroup()
# change names to the names wanted by makeRiver
names(the_data) <- c("col1", "col2", "Value")
# node ID need to be characters I think
c1 <- unique(the_data$col1)
c2 <- unique(the_data$col2)
nodes_ref <- data_frame(fullname = c(c1, c2)) %>%
mutate(position = rep(c(1, 2), times = c(length(c1), length(c2)))) %>%
mutate(ID = LETTERS[1:n()])
edges <- the_data %>%
left_join(nodes_ref[ , c("fullname", "ID")], by = c("col1" = "fullname")) %>%
rename(N1 = ID) %>%
left_join(nodes_ref[ , c("fullname", "ID")], by = c("col2" = "fullname")) %>%
rename(N2 = ID) %>%
as.data.frame(stringsAsFactors = FALSE)
rp <- makeRiver(nodes = as.vector(nodes_ref$ID), edges = edges,
node_labels = nodes_ref$fullname,
# manual vertical positioning by parties. Look at
# nodes_ref to see the order in which positions are set.
# This is a pain, so I just let it stay with the defaults:
# node_ypos = c(4, 1, 1.8, 3, 6, 7, 5, 4, 1, 1.8, 3, 6, 7),
node_xpos = nodes_ref$position,
# set party colours; all based on those in nzelect::parties_v:
node_styles = list(C = list(col = "#d82a20"), # red labour
D = list(col = "#00529F"), # blue national
E= list(col = "black"), # black NZFirst
B = list(col = "#098137"), # green
J = list(col = "#d82a20"), # labour
I = list(col = "#098137"), # green
K = list(col = "#00529F"), # national
L = list(col = "black"))) # NZ First
# Turn the text horizontal, and pale grey
ds <- default.style()
ds$srt <- 0
ds$textcol <- "grey95"
mygp <- gpar(col = "grey75")
# using PNG rather than SVG as vertical lines appear in the SVG version
par(bg = "grey40")
# note the plot_area argument - for some reason, defaults to using only half the
# vertical space available, so set this to higher than 0.5!:
plot(rp, default_style = ds, plot_area = 0.9)
title(main = "Self-reported party vote in 2011 compared to 2014",
col.main = "white", font.main = 1)
grid.text(x = 0.15, y = 0.1, label = "2011 party vote", gp = mygp)
grid.text(x = 0.85, y = 0.1, label = "2014 party vote", gp = mygp)
grid.text(x = 0.95, y = 0.03,
gp = gpar(fontsize = 7, col = "grey75"), just = "right",
label = "Source: New Zealand Election Study, analysed at https://ellisp.github.io")
#=======================sankeyD3 version====================
nodes_ref2 <- nodes_ref %>%
mutate(ID = as.numeric(as.factor(ID)) - 1) %>%
as.data.frame()
edges2 <- the_data %>%
ungroup() %>%
left_join(nodes_ref2[ , c("fullname", "ID")], by = c("col1" = "fullname")) %>%
rename(N1 = ID) %>%
left_join(nodes_ref2[ , c("fullname", "ID")], by = c("col2" = "fullname")) %>%
rename(N2 = ID) %>%
as.data.frame(stringsAsFactors = FALSE) %>%
mutate(Value = Value / sum(Value) * 100)
pal <- 'd3.scaleOrdinal()
.range(["#DCDCDC", "#098137", "#d82a20", "#00529F", "#000000", "#DCDCDC",
"#DCDCDC", "#098137", "#d82a20", "#00529F", "#000000", "#DCDCDC"]);'
sankeyNetwork(Links = edges2, Nodes = nodes_ref2,
Source = "N1", Target = "N2", Value = "Value",
NodeID = "fullname",
NodeGroup = "fullname",
LinkGroup = "col2",
fontSize = 12, nodeWidth = 30,
colourScale = JS(pal),
numberFormat = JS('d3.format(".1f")'),
fontFamily = "Calibri", units = "%",
nodeShadow = TRUE,
showNodeValues = FALSE,
width = 700, height = 500)
#=======other by the by analysis==================
# Age density plot by party vote
# Remember to weight by the survey weights - in this case it controls for
# the under or over sampling by age in the original design.
nzes5 %>%
ggplot(aes(x = dage, fill = partyvote2014, weight = weight / sum(nzes5$weight))) +
geom_density(alpha = 0.3) +
facet_wrap(~partyvote2014, scales = "free_y") +
scale_fill_manual(values = parties_v) +
theme(legend.position = "none") +
labs(x = "Age at time of 2014 election",
caption = "Source: New Zealand Election Study") +
ggtitle("Age distribution by Party Vote in the 2014 New Zealand General Election")