Comparing two timeseries-generating blackboxes
In my last post I talked about how this question on Cross-Validated got me interested. Basically the challenge is to compare two data generating models to see if they are essentially the same. Since then I’ve noticed that this problem comes up in a number of other contexts too; for example, this New Zealand Treasury Working paper by Kam Leong Szeto on Estimating New Zealand’s Output Gap Using a Small Macro Model at one point runs lots of sets of two simulations of the New Zealand economy and compares the distribution of the standard deviations of various interesting estimated parameters, and of their first order autocorrelation coefficients (ie the correlation of the series with the lagged version of itself):
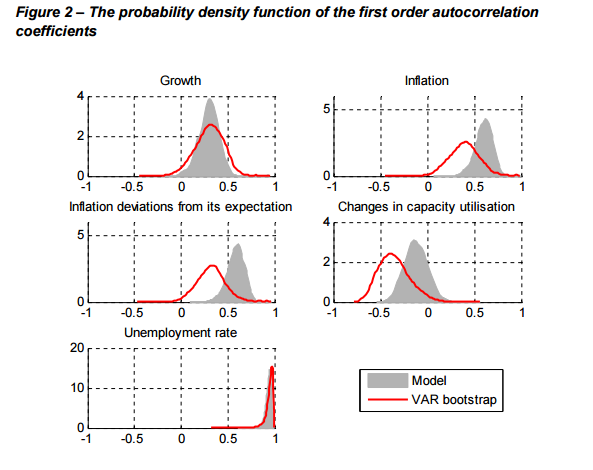
This latter process of comparing autocorrelation coefficients is similar to what user333700 suggested on Cross-Validated, and is what I showed in my last post is not a bullet-proof means of comparing time series; most importantly, linear combinations of a time series will have the same autocorrelation function. So one of Szeto’s models might be generating values 10 percent larger than the other, but still having the same autocorrelation coefficients in his Figure 2 above. However, as he also compares the standard deviations of the simulated values of interest, he fixes some of that problem (not all of it - just adding a constant, for example, would leave him with identical autocorrelation coefficients and standard deviations, but very different results).
My example black boxes
To explore this for a more general solution, I first need something to try it on. I made two functions that generate data that is close enough to wonder if they are the same, but which a good enough method can distinguish between. I define for myself two similar but different time series, one an ARIMA(2,1,1) process and the other an ARIMA(1,1,2). Here’s one instance each coming out from those black boxes. Notice that they look very different!

library(dplyr)
library(tidyr)
library(ggplot2)
library(showtext) # for fonts
font.add.google("Poppins", "myfont")
showtext.auto()
theme_set(theme_light(base_family = "myfont"))
bb1 <- function(n = 1000){
# ARIMA(2, 1, 1) with drift
cumsum(arima.sim(model = list(ar = c(0.5, -0.2), ma = 0.3), n = n) + 0.10)
}
bb2 <- function(n = 1000){
# ARIMA(1, 1, 2) with drift
cumsum(arima.sim(model = list(ar = c(0.5), ma = c(0.3, -0.1)), n = n) + 0.04)
}
# one example each from both of my black boxes
set.seed(134)
par(mfrow = c(2, 1), family = "myfont", mar = c(4, 5, 1, 1))
plot.ts(bb1(), bty = "l", main = "One instance from blackbox 1")
plot.ts(bb2(), bty = "l", main = "One instance from blackbox 2")So those two series look obviously different, right, no need for any fancy stats to say they’re different… except that if you make lots of examples of them, you get a different result each time. Here’s how they look when we do 100 instances of each one, 500 observations long each:

# create skeleton of dataframe to hold data:
the_data <- data_frame(blackbox1 = numeric(), blackbox2 = numeric(), trial = numeric(), time = numeric())
# populate with simulated versions:
reps <- 100
n <- 500
set.seed(123) # for reproducibility
for(i in 1:reps){
tmp <- data_frame(blackbox1 = bb1(n), blackbox2 = bb2(n), trial = i, time = 1:n)
the_data <- rbind(the_data, tmp)
}
# gather into long tidy format
the_data_m <- the_data %>%
gather(source, value, -trial, -time)
# show the data from the two black boxes:
the_data_m %>%
ggplot(aes(x = time, y = value, colour = as.character(trial))) +
facet_wrap(~source) +
geom_line(alpha = 0.3) +
geom_smooth(se = FALSE, method = "loess") +
theme(legend.position = "none")Comparison method
My method of comparison is based on assuming blackbox1 is the known good generator and we want to see if blackbox2 is plausibly the same. I do these steps:
- calculate the average value at each point in time of the various instances of blackbox1, and the standard deviation of blackbox1’s values at that point.
- calculate how the absolute value of how different each instance of both series is from that average value, standardised by the standard deviation.
- correct that difference value for blackbox1 by multiplying it by the (number of instances) / (number of instances - 1) , to control for the fact that the centre was defined by blackbox1 data and hence blackbox1 has a head start in trying to be close to the defined centre. In effect, I give it a degrees-of-freedom correction.
- analyse the distribution of the differences to see if the instances of blackbox2 seem, on average, to be further away from the centres than are the instances of blackbox1.
Here’s how it looks. In this case, blackbox2’s differences from the known-good centre is generally higher (ie displaced to the right in this density graph) than is blackbox1’s:

difference <- the_data_m %>%
left_join(
the_data %>%
group_by(time) %>%
summarise(centre_1 = mean(blackbox1),
sd_1 = sd(blackbox1)),
by = "time"
) %>%
# bias correction because the centres are defined from blackbox1's data,
# hence on average they will always be a little closer to them
mutate(correction = ifelse(source == "blackbox1", max(trial) / (max(trial) - 1), 1)) %>%
group_by(trial, source)%>%
summarise(
meandiff = mean(abs(value - centre_1) / sd_1 * correction))
ggplot(difference, aes(x=meandiff, colour = source)) +
geom_density() +
ggtitle("Mean absolute standardise difference\nat each time point from the average of\nblackbox1 at that point")I want a more formal method of comparing the two and testing for data to reject a hypothesis of the two black boxes being the same. An obvious candidate is a linear regression model with the mean corrected standardised difference of each trial instance as response variable, and source (blackbox 1 or 2) as the explanatory variable. However, the truncated nature of the differences (they are absolute differences, so are all zero or higher and there is a long tail) mean that ordinary least squares is probably a poor way of performing inference on them. This is shown (probably unnecessarily) in the top right of the standard set of diagnostic plots below:

model1 <- lm(meandiff ~ source, data = difference)
par(mfrow=c(2, 2), family = "myfont")
plot(model1) # definitely normality assumption violated, so let's try something a bit more robustThere are various possible solutions but I go with using Venables and Ripley’s implementation of an M estimator in rlm(), in combination with bootstrapping. This minimises any assumptions I need to make about distributions, and controls for awkward outliers.
library(MASS)
library(boot)
R <- 2000
booted_robust <- boot(difference,
statistic = function(data, w){
model <- rlm(meandiff ~ source, data = data[w, ])
return(model$coefficients["sourceblackbox2"])
}, R = R)
# p-value for one sided test of H-null no difference v. H-alt blackbox2
# is more different from blackbox1 centresthan blackbox1:
1 - sum(booted_robust$t > 0) / RFor the given example, the p-value comes out as zero ie there is no chance that the observed differences could be a result of the same blackbox generating different data at random. Re-running the exercise with various tests (eg comparing bb1() with bb1()) shows that the process is pretty good at not returning false positives; and it does correctly identify any true positives I’ve given it so far. More rigorous testing would be possible, but…
Conclusions
After all this, I’m not sure where I’ve come out. I think I have a pretty good method for telling whether two black box time series generators are identical; but does it really matter? Going back to the original question on Cross-Validated, I guess the OP knew that they were different. So proving this tells him nothing. Black box 2 is a model of Black box 1, and the question really is not whether it is right, but whether it is “right enough”. Unfortunately, I don’t think there’s a rigorous objective way of determining that. Some kind of cost function for wrongness could be developed and assessed against, but the choice of cost function will probably be subjective (maybe not, depending on the field I suppose).
This is not unrelated to a common issue in modern data analysis - with enough data, any hypothesis test is “significant”. The more so in this situation, where we control the data generating processes and hence can keep creating more data until a difference, no matter how subtle, is conclusively proven.
My feel is that this sort of problem needs to go back to expert judgement aided by the best exploratory analytics graphics available. So the approach by Szeto in the Treasury working paper linked to above is a good one, although I think that more than the standard deviations and autocorrelations need to be graphed. It’s known that the two black boxes are different - all statistics can do is help you in the judgement of whether the difference is too much or not. So the best benefit of all the text and code above might be to give a few ideas for starting points in how to explore these differences.